Desde o primeiro dia do SEO, os profissionais de marketing tentaram determinar quais fatores o Google leva em consideração ao classificar os resultados nas SERPs. Neste novo Whiteboard Friday, Russ Jones analisa a teoria por trás desses fatores de classificação e nos dá algumas definições e vocabulário aprimorados para usar ao discuti-los.
Clique na imagem do quadro acima para abrir uma versão em alta resolução em uma nova guia.
Transcrição de vídeo
Olá amigos. Bem-vindo de volta a outro quadro-negro na sexta-feira. Hoje, vamos falar sobre os fatores de classificação e a teoria por trás deles e, esperançosamente, superar alguns desses, digamos, controvérsias, que surgiram ao longo dos anos, quando na verdade só falamos um do outro.
Você vê, os fatores de classificação estão conosco desde o primeiro dia da otimização de mecanismos de pesquisa. Tentamos como SEO identificar exatamente o que influencia o algoritmo. Bem, isso é o que vamos repassar hoje, mas vamos tentar encontrar melhores definições e vocabulário para que não falemos uns com os outros e não estejamos constantemente batendo uns nos outros. refere-se a correlação e não causalidade, ou algum outro tipo de nuance que realmente não importa.
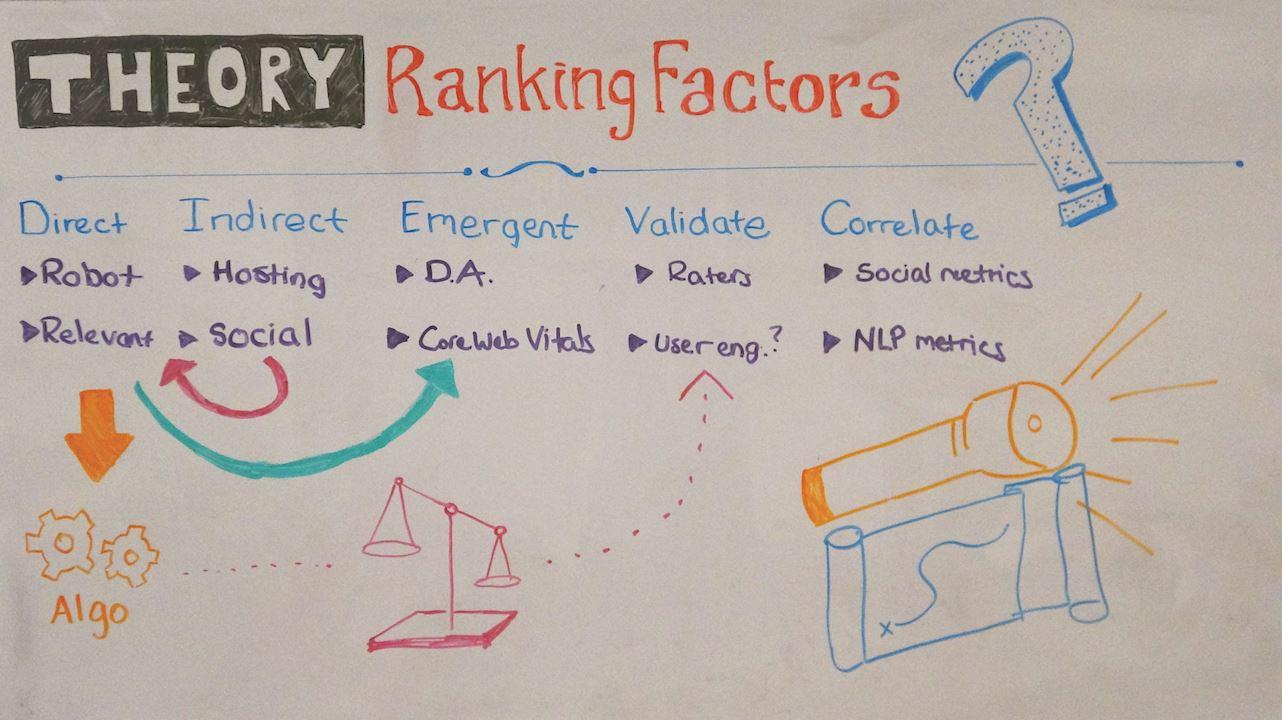
Direto
Portanto, vamos começar com os fatores diretos de classificação. Este é o tipo mais limitado de compreensão dos fatores de classificação. Isso não significa que esteja errado, é bastante restritivo. Um fator de classificação direto seria algo que o Google mede e influencia diretamente o desempenho do resultado da pesquisa.
Portanto, um exemplo clássico seria, na verdade, seu arquivo robots.txt. Se você fizer uma alteração em seu arquivo robots.txt e, digamos, não permitir o Google, isso terá um impacto direto em seu desempenho no Google. Ou seja, seu site vai desaparecer.
O mesmo é na maior parte com relevância. Talvez não saibamos exatamente o que o Google está usando para medir a relevância, mas sabemos que, se você melhorar a relevância do seu conteúdo, terá maior probabilidade de obter uma classificação mais elevada. Esses são o que chamaríamos de fatores diretos de classificação. Mas obviamente há muito mais do que isso.
O Google adicionou mais e mais recursos ao seu mecanismo de busca. Eles mudaram a maneira como seu algoritmo funciona. Eles adicionaram mais e mais aprendizado de máquina. Então, fiz o meu melhor para tentar encontrar algum novo vocabulário que pudéssemos usar para descrever os diferentes tipos de fatores de classificação que frequentemente discutimos em nossas várias comunidades ou online.
Indireto
Obviamente, se houver fatores diretos de classificação, parece que deve haver fatores indiretos de classificação. E esses são apenas fatores de classificação ou intervenções que são removidos assim que você pode executar e não influenciam diretamente o algoritmo, mas influenciam alguns dos fatores diretos de classificação que influenciam o algoritmo.
Acho que um exemplo clássico disso é a acomodação. Digamos que você tenha um site que está começando a ficar mais popular e é hora de gastar aquele dólar por mês com a hospedagem cPanel que você assinou quando começou seu blog. Bem, você pode escolher mover para, digamos, um host dedicado que tenha muito mais RAM e CPU e pode lidar com mais threads para fazer tudo funcionar mais rápido.
O tempo até o primeiro byte é mais rápido. Bem, o Google não tem um algoritmo que olha para o servidor e identifica exatamente quantos núcleos de CPU existem. Mas há uma série de fatores diretos de classificação, aqueles que talvez estejam relacionados à experiência do usuário ou talvez à velocidade da página, que podem ser influenciados pelo seu ambiente de hospedagem.
Consequentemente, temos boas razões para acreditar que melhorar o ambiente de sua acomodação pode ter uma influência positiva em sua classificação de pesquisa. Mas não seria uma influência direta. Seria indireto.
O mesmo aconteceria com as redes sociais. Embora tenhamos certeza de que o Google não diz apenas “Ok, quem for o mais popular no Twitter será classificado”, há um bom motivo para acreditar que você investe seu tempo, dinheiro e energia promovendo seu conteúdo nas redes sociais. pode influenciar os resultados da sua pesquisa.
Um exemplo perfeito disso seria a promoção de um artigo no Facebook, que é então escolhido por alguma postagem online e, em seguida, vinculado ao seu site. Portanto, embora a atividade de mídia social em si não tenha influenciado diretamente seus resultados de pesquisa, ela influenciou os links, e esses links influenciaram seus resultados de pesquisa.
Portanto, podemos chamar esses fatores de classificação de indiretos. Como cortesia, por favor, quando alguém falar sobre mídia social como um fator de classificação, apenas não presuma imediatamente que isso significa que é um fator de classificação direto. Muito bem, eles podem significar que é indireto e você pode pedir que eles esclareçam: “Bem, o que você quer dizer? Você acha que o Google mede a atividade nas redes sociais ou está dizendo que fazer um trabalho melhor nas redes sociais provavelmente influencia os resultados? pesquisar de uma forma ou de outra? ”
Portanto, isso faz parte do processo de desvendar as diferenças entre os fatores de classificação. Dá-nos a capacidade de nos comunicarmos sobre eles de uma forma que, digamos, não confundamos o que queremos dizer com palavras.
Emergente
Agora, o terceiro tipo é provavelmente o mais controverso e, na verdade, concordo com isso. Adoraria falar nos comentários ou no Twitter sobre o que exatamente quero dizer com fatores emergentes de classificação. Acho importante que sejamos claros sobre isso de alguma forma, forma ou forma, porque acho que se tornará cada vez mais importante à medida que o aprendizado de máquina se torna cada vez mais importante como parte do algoritmo do Google.
Muitos, muitos anos atrás, otimizadores de mecanismos de pesquisa como eu notaram que as páginas da web em domínios que tinham forte autoridade de link pareciam ter um bom desempenho nos resultados de pesquisa orgânica, mesmo quando a página em si não era particularmente boa, não tinha links externos particularmente bons. – ou nenhum, e nem mesmo tinha links internos particularmente bons.
Quer dizer, era uma página quase órfã. Então, os SEOs começaram a se perguntar se havia algum tipo de atributo de nível de domínio que o Google estava usando como fator de classificação. Não podemos saber disso. Bem, podemos perguntar ao Google, mas só podemos esperar que eles nos digam.
Então, na Moz, o que decidimos fazer foi tentar identificar uma série de métricas de link de nível de domínio que realmente prevêem a probabilidade de uma página ter um bom desempenho nos resultados de pesquisa. Chamamos isso de fator de classificação emergente, ou pelo menos eu chamo de fator de classificação emergente, porque obviamente o Google não tem um recurso semelhante a autoridade de domínio específico em seu algoritmo.
Mas, ao contrário, eles também têm muitos dados sobre links que apontam para páginas diferentes no mesmo domínio. O que eu acho que está acontecendo é o que eu chamaria de fator de classificação emergente, que é onde, digamos, a influência de várias métricas diferentes, nenhuma das quais tem um propósito específico de criar algo, acaba sendo fácil de medir e medir. fale deles como um fator de classificação emergente, e não como parte de todos os seus elementos constituintes.
Agora, isso foi meio complicado, então deixe-me dar um exemplo. Quando você está fazendo um molho para cozinhar, uma das partes mais comuns é fazer um roux. Um roux seria uma mistura, geralmente pesos iguais de farinha e gordura, e você usaria isso para engrossar o molho.
Agora, você poderia escrever um livro de receitas inteiro sobre molhos e nunca usar a palavra “roux”. Apenas não use e descreva o processo de produzir um roux cem vezes, mas nunca use a palavra “roux”, porque “roux” descreve esse estado intermediário. Mas torna-se muito, muito útil como chef ser capaz de dizer a outro chef (ou a um segundo chef, ou a um cozinheiro em seu livro de receitas), “fazer um roux” e, em seguida, que gordura específica você está usando, seja manteiga. ou óleo ou algo parecido.
Então, a analogia aqui é que não há nada chamado roux dentro do molho. O que está no molho é a gordura e a farinha. Mas, ao mesmo tempo, é muito conveniente chamá-lo de roux. Na verdade, podemos usar a palavra “roux” para saber muito sobre um determinado prato, sem nunca falar sobre os ingredientes reais da farinha e da gordura.
Por exemplo, podemos ter certeza de que, se um roux for pedido em um determinado prato, esse prato provavelmente não é bacon porque não é um molho. Portanto, acho que estou tentando chegar aqui é que muito do que estamos falando sobre os fatores de classificação é o uso de uma linguagem conveniente e valiosa para determinados fins.
Como o DA, é valioso para ajudá-lo a prever os resultados da pesquisa, mas não precisa realmente fazer parte do algoritmo para fazer isso. Na verdade, acho que há um exemplo muito interessante acontecendo agora, e estamos prestes a ver uma mudança nas categorias, que são Core Web Vitals.
O Google vem aumentando a velocidade da página há algum tempo e nos forneceu várias iterações de diferentes tipos de métricas para determinar a velocidade de carregamento de uma página. No entanto, o que parece ser o caso é que o Google decidiu não promover etapas individuais e particulares que um site poderia tomar para acelerar, mas em vez disso, quer maximizar ou minimizar um determinado valor emergente que vem da fusão de todos. dessas etapas.
Sabemos que os três tipos diferentes de Core Web Vitals são: primeiro atraso de entrada, pintura com conteúdo maior e mudança cumulativa de layout. Então, vamos falar sobre o terceiro. Se você já esteve no seu celular e notou o carregamento do texto antes de certos outros aspectos e começou a lê-lo e tentar rolar para baixo e assim que você colocou o dedo lá, um anúncio apareceu porque o anúncio demorou mais para carregar e você está apenas empurrando a página, bem, isso é uma mudança de design, e o Google aprendeu que os usuários simplesmente não gostam disso. Portanto, embora eles não conheçam todos os fatores individuais subjacentes que são responsáveis pela mudança cumulativa de design, eles sabem que essa medida existe, o que explica tudo, é um ótimo atalho e uma maneira realmente eficaz de determinar se o usuário vai ou nenhum aproveite sua experiência nessa página.
Este seria um fator de classificação emergente. Agora, o interessante é que o Google decidiu que esse fator de classificação emergente se tornará um fator de classificação direto em 2021. Eles moverão esses fatores descritivos que são amálgamas de muitas pequenas coisas e os farão influenciar diretamente a pesquisa. resultados.
Portanto, podemos ver como esses diferentes tipos de fatores de classificação podem se mover para frente e para trás entre as categorias. Voltando à questão da autoridade de domínio. Agora o Google deixou claro que não usa a autoridade de domínio do Moz, claro que não, e não tem uma métrica semelhante para autoridade de domínio. No entanto, não há nada que diga que em algum ponto eles falharam em construir exatamente isso, algum tipo de métrica baseada em link no nível do domínio que é usada para informar como classificar certas páginas.
Portanto, um fator de classificação emergente não está preso nessa categoria. Pode mudar. Bem, isso é o suficiente sobre os fatores de classificação emergentes. Esperamos poder falar mais sobre isso nos comentários.
Validando
O próximo tipo que gostaria de analisar é o que eu chamaria de fator de classificação de validação. Este é outro que tem sido bastante polêmico, que é a lista de Diretrizes de Classificação de Qualidade de coisas que importam, e provavelmente o mais falado é E-A-T – Experiência, Autoridade e Confiabilidade.
Bem, o Google deixou claro que eles não apenas não medem o EAT (ou pelo menos, pelo que entendi, eles não têm métricas que visam especificamente o EAT), não apenas não fazem, também, quando coletam os dados dos avaliadores de qualidade sobre Quer os SERPs que procuram atendam ou não a essas classificações, eles não treinam seu algoritmo contra os dados marcados que vêm de seus avaliadores de qualidade, o que me surpreende.
Parece-me que, se você tivesse muitos dados marcados sobre qualidade, experiência e autoridade, talvez queira treiná-los para isso, mas talvez o Google tenha achado que não era muito produtivo. No entanto, sabemos que o Google se preocupa com o E-A-T e também temos evidências anedóticas.
Ou seja, os webmasters notaram ao longo do tempo, especialmente nos setores do tipo “seu dinheiro ou sua vida”, que a experiência e a autoridade parecem ter importância de alguma maneira, forma ou forma. Então, eu gosto de chamar esses fatores de classificação de validação porque o Google os usa para validar a qualidade dos SERPs e dos sites que eles estão classificando, mas na verdade não os usa de forma direta ou indireta para influenciar os resultados de pesquisa.
Agora, eu tenho um interessante aqui, que é o que eu chamaria de engajamento do usuário, e o motivo pelo qual coloquei aqui é porque ainda é um fator de classificação bastante controverso. Não temos certeza de como o Google o usa, embora recebamos algumas dicas de vez em quando, como Core Web Vitals.
Se esses dados forem coletados a partir do comportamento real do usuário no Chrome, então temos uma ideia de como o envolvimento do usuário pode ter um impacto indireto no algoritmo, porque o envolvimento do usuário mede Core Web Vitals, que, a partir de 2021, variam para influenciar diretamente os resultados da pesquisa.
Correlação
Então a validação é essa quarta categoria de fatores de ranking, e a última, a que eu acho mais polêmica, são os correlatos. Sempre entramos neste argumento: “correlação não é igual a causalidade”, e me parece que é a afirmação de que quem só sabe uma coisa sobre estatística sabe, e é por isso que sempre o diz quando surge algo sobre correlação. .
Sim, correlação não implica causalidade, mas isso não significa que não seja muito, muito útil. Então, vamos falar sobre métricas sociais. Este é um dos clássicos. Fizemos vários estudos de fatores de classificação várias vezes e encontramos uma relação direta e forte entre coisas como curtidas no Facebook ou as vantagens do Google nas classificações.
Tudo bem. Agora quase todos entenderam imediatamente que o motivo pelo qual um site teria mais marcações no Google+ e mais curtidas no Facebook seria porque ele se classifica. Ou seja, não é o Google que sai e conta com a API do Facebook para determinar como os sites serão classificados em seu mecanismo de busca.
Ao contrário, um bom desempenho em seu mecanismo de busca gera tráfego, e esse tráfego tende a gostar da página. Portanto, entendo a frustração que existe quando os clientes começam a perguntar: “Bem, essas duas coisas se correlacionam. Por que não estou recebendo mais curtidas?”
Eu entendo, mas isso não significa que não seja útil de outras maneiras. Vou dar um bom exemplo. Se você está bem classificado para uma palavra-chave, mas suas métricas de mídia social são piores do que as de seus concorrentes, bem, isso significa que algo está acontecendo naquela situação que está fazendo com que seus usuários interajam melhor com os sites de seus concorrentes do que os de seus concorrentes. seu, e isso é importante saber.
Isso pode não mudar sua classificação, mas pode mudar sua taxa de conversão. Isso pode aumentar a probabilidade de ser encontrado nas redes sociais. Ainda mais, pode influenciar os resultados da pesquisa. Porque, quando você reconhece o motivo de não receber curtidas em sua página, é porque você tem um código corrompido, então o botão do Facebook não funciona, e então você o adiciona e começa a compartilhar e mais e mais pessoas estão interagindo e link para o seu conteúdo, então começamos a ter esse efeito indireto na sua classificação.
Portanto, sim, correlação não é o mesmo que causalidade, mas há muito valor nisso. Há uma nova área que acho que será muito importante para isso. Essas serão métricas de processamento de linguagem natural. São várias tecnologias diferentes que estão na vanguarda. Bem, alguns são mais velhos. Alguns são mais novos. Mas eles nos permitem prever o quão bom é o conteúdo.
Agora, provavelmente não vamos adivinhar a maneira exata como o Google mede a qualidade do conteúdo. Quer dizer, a menos que apareça um documento vazado ou algo assim, provavelmente não teremos tanta sorte. Mas isso não significa que não possamos ser realmente produtivos se tivermos vários correlatos, e esses correlatos podem ser usados para nos guiar.
Desenhei um pequeno mapa aqui para servir de exemplo. Imagine que é noite e você está acampando e decide fazer uma caminhada rápida, e carrega com você, digamos, uma bandeira ou uma série de bandeiras, e marca o caminho à medida que segue para que, quando chegar mais tarde, possa ligar sua lanterna e apenas siga as bandeiras, pegando-as, para levá-lo de volta ao acampamento.
Mas fica muito escuro, e então você percebe que deixou sua lanterna no acampamento. O que vai fazer? Bem, temos que encontrar uma maneira de nos guiar de volta ao acampamento. Agora, obviamente, as bandeiras teriam sido a melhor situação, mas há muitas coisas que não são o próprio acampamento ou a própria estrada, mas que ainda seriam de grande ajuda para nos levar de volta ao acampamento. Por exemplo, digamos que você acabou de apagar o fogo depois de deixar o acampamento. Bem, o cheiro de fumaça é uma ótima maneira de encontrar o caminho de volta ao acampamento, mas fumaça não é acampamento. Não causou o acampamento. Ele não construiu o acampamento. Não é o caminho. Ele não criou o caminho. Na verdade, a própria trilha de fumaça provavelmente está bem longe, mas assim que você descobrir onde ela o cruza, você pode seguir aquele cheiro. Bem, nesse caso, é realmente valioso, embora esteja ligeiramente correlacionado com exatamente onde você precisa ir.
Bem, o mesmo é verdade quando falamos sobre métricas de PNL ou métricas de mídia social. Embora possam não ser importantes em termos de influência direta nos resultados da pesquisa, eles podem orientar seu caminho. Eles podem ajudá-lo a tomar melhores decisões. O que você deve evitar é manipular esses tipos de métricas para seu próprio bem, porque sabemos que os correlatos estão mais distantes dos fatores diretos de classificação, pelo menos quando sabemos que a correlação em si não é um fator de classificação direto.
Tudo bem. Eu sei que é muito para o estômago, muito para absorver. Espero que tenhamos algum material para discutir abaixo nos comentários e estou ansioso para falar mais com você. Boa sorte. Adeus.
Transcrição de vídeo por Speechpad.com