Uma das decisões mais difíceis de tomar em qualquer área é escolher conscientemente não cumprir um prazo. Nos últimos meses, uma equipe de alguns dos mais brilhantes engenheiros, cientistas de dados, gerentes de projeto, editores e profissionais de marketing trabalhou para uma nova data de lançamento do Page Authority (PA) de 30 de setembro de 2020 O novo modelo é excepcional em quase todos os sentidos até o AP atual, mas nossa última medida de controle de qualidade revelou uma anomalia que não poderíamos ignorar.
Como resultado, tomamos uma decisão difícil atrasar o lançamento do Page Authority 2.0. Portanto, deixe-me refazer nossos passos sobre como chegamos aqui, onde isso nos deixa e como pretendemos prosseguir.
Veja um problema antigo com novos olhos
Historicamente, a Moz tem usado o mesmo método repetidamente para construir um modelo de Autoridade de Página (bem como Autoridade de Domínio). A vantagem desse modelo era a simplicidade, mas deixava muito a desejar.
Modelos de autoridade de página anterior treinados contra SERPs, tentando prever se uma URL seria classificada em relação a outra, com base em um conjunto de métricas de link calculadas a partir do índice de backlink do Link Explorer. Um problema chave com esse tipo de modelo era que ele não conseguia lidar de forma significativa com a força máxima de um determinado conjunto de métricas de link.
Por exemplo, imagine os URLs mais poderosos da Internet em termos de links: páginas iniciais do Google, Youtube, Facebook ou os URLs de compartilhamento de botões de mídia social seguidos. Não há SERPs que colocam esses URLs uns contra os outros. Em vez disso, esses URLs extremamente poderosos geralmente são classificados em primeiro lugar, seguidos por páginas com métricas dramaticamente mais baixas. Imagine se Michael Jordan, Kobe Bryant e Lebron James enfrentassem jogadores do ensino médio. Cada um venceria todas as vezes. Mas teríamos grande dificuldade em extrapolar esses resultados se Michael Jordan, Kobe Bryant ou Lebron James venceriam em partidas um contra um.
Quando recebemos a tarefa de revisitar a Autoridade de Domínio, finalmente escolhemos um modelo com o qual tínhamos muita experiência: o método de treinamento SERP original (embora com uma série de ajustes). Com o Page Authority, decidimos usar um método de treinamento completamente diferente ao prever qual página teria o maior tráfego orgânico total. Este modelo tinha várias qualidades promissoras, como ser capaz de comparar URLs que não aparecem no mesmo SERP, mas também tinha outras dificuldades, como uma página com alto valor de link, mas estava simplesmente em uma área de assunto que era pesquisada com pouca frequência. Abordamos muitas dessas preocupações, como melhorar o conjunto de treinamento, para contabilizar a competitividade usando uma métrica sem vínculo.
Medindo a qualidade da nova Autoridade da Página
Os resultados foram e são muito promissores.
Primeiro, o novo modelo obviamente previu a probabilidade de uma página ter tráfego orgânico mais valioso do que outra. Isso era esperado, porque o novo modelo visava esse objetivo específico, enquanto a Autoridade da Página Atual estava simplesmente tentando prever se uma página seria classificada em detrimento de outra.

Em segundo lugar, descobrimos que o novo modelo previu se uma página teria uma classificação melhor do que a autoridade de página anterior. Isso foi especialmente satisfatório, pois pôs fim a muitas de nossas preocupações de que o novo modelo teria desempenho inferior ao dos CQs anteriores devido ao novo modelo de treinamento.
Quão melhor é o novo modelo para prever SERP do que o PA atual? A cada intervalo, até a posição 4 x 5, o novo modelo empatou ou superou o modelo atual. Nunca perdido.

Tudo parecia ótimo. Em seguida, começamos a analisar os outliers. Eu gosto de chamar isso de “algo parece estúpido?” prova. O aprendizado de máquina comete erros, assim como os humanos, mas os humanos tendem a cometer erros de uma maneira muito particular. Quando um humano comete um erro, geralmente entendemos exatamente por que foi cometido. Este não é o caso com AA, especialmente com redes neurais; Extraímos URLs com altas autoridades de página no novo modelo que tinha tráfego orgânico zero e os incluímos no conjunto de treinamento para aprender como detectar esses erros. Rapidamente vimos o número ímpar de 90+ AP cair para um número muito mais razoável de 60 e 70 … outra vitória.
Estávamos em um último teste.
O problema com a marca
Algumas das palavras-chave mais populares na web são navegação. As pessoas procuram o Google pelo Facebook, YouTube e até o próprio Google. Essas palavras-chave são pesquisadas um número astronômico de vezes em relação a outras palavras-chave. Posteriormente, um punhado de marcas muito poderosas pode ter um grande impacto em um modelo que considera o volume total de pesquisas como parte de seu objetivo principal de treinamento.
O último teste envolve a comparação da Autoridade da Página atual com a nova Autoridade da Página, para determinar se existem valores discrepantes estranhos (onde PA mudou drasticamente e sem motivo óbvio). Primeiro, vamos ver uma comparação simples do domínio raiz vinculando o LOG com a Autoridade da Página.
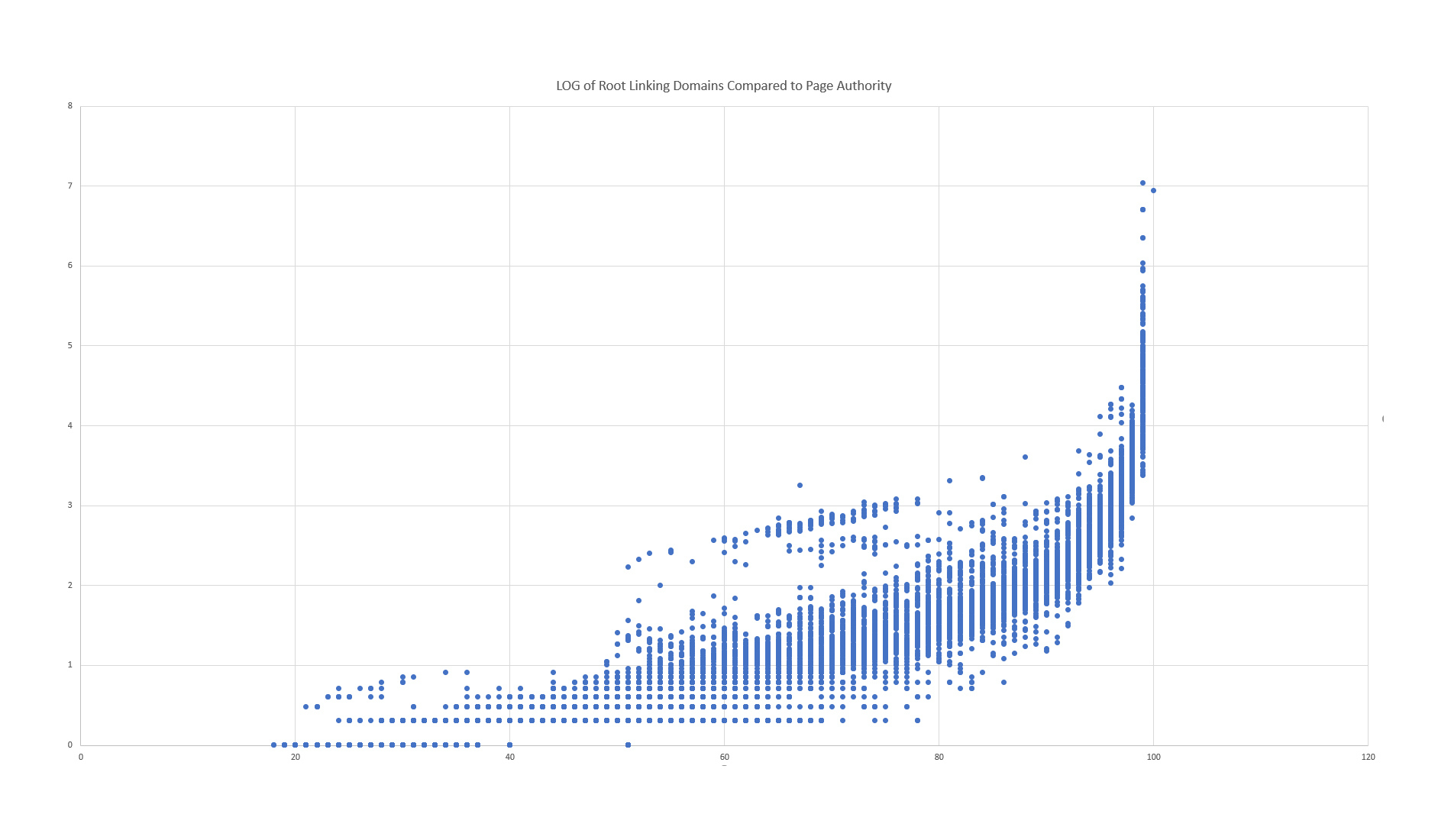
Não é ruim. Vemos uma correlação geralmente positiva entre vincular domínios raiz e autoridade de página. Mas você consegue identificar as esquisitices? Vá em frente, espere um minuto …
Existem duas anomalias que se destacam neste gráfico:
- Há uma lacuna curiosa que separa a distribuição de URL principal e os outliers superior e inferior.
- A maior variação para uma única pontuação está no PA 99. Há um grande número de PA 99 com uma ampla variedade de domínios raiz de link.
Aqui está uma visualização que ajudará a identificar essas anomalias:
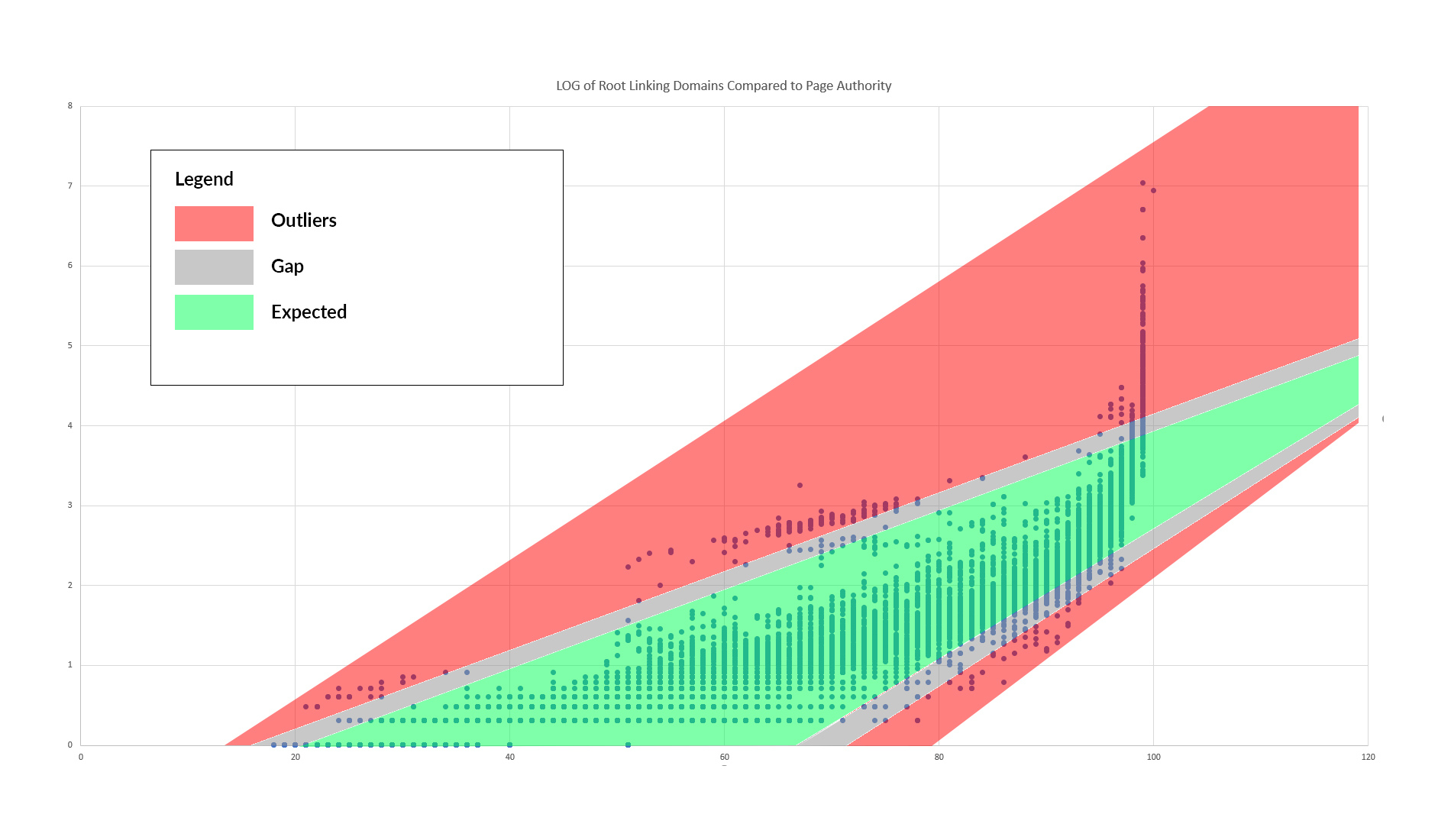
Os espaços cinza entre o verde e o vermelho representam esta estranha lacuna entre a maior parte da distribuição e outliers. Outliers (em vermelho) tendem a se agrupar, especialmente acima da distribuição principal. E, claro, podemos ver a má distribuição no topo dos PA 99s.
Observe que esses problemas não são suficientes para tornar o novo modelo de Autoridade da Página menos preciso do que o modelo atual. No entanto, após um exame mais detalhado, descobrimos que os erros produzidos pelo modelo foram significativos o suficiente para influenciar negativamente as decisões de nossos clientes. É melhor ter um modelo um pouco desatualizado em todos os lugares (porque os ajustes de SEO não são incrivelmente ajustados) do que um modelo que está correto em todos os lugares, mas estranhamente incorreto em um número limitado de casos.
Felizmente, temos certeza de qual é o problema. Parece que os APs na página inicial estão desproporcionalmente inflados e o culpado potencial é o pacote de treinamento. Não podemos ter certeza de que essa é a causa até concluirmos a reciclagem, mas é uma vantagem sólida.
As boas e más notícias
Estamos em boa forma na medida em que temos vários modelos candidatos que superam a Autoridade de Página existente. Estamos no ponto de depurar, não construir modelos. No entanto, não enviaremos uma nova pontuação até termos certeza de que ela apontará a direção certa para nossos clientes. Estamos cientes das decisões que nossos clientes tomam com base em nossas métricas, não apenas se as métricas atendem a alguns critérios estatísticos.
Diante de tudo isso, decidimos adiar o lançamento do Page Authority 2.0. Isso nos dará tempo para abordar essas principais preocupações e produzir uma métrica estelar. Frustrante? Sim, mas também necessário.
Como sempre, agradecemos sua paciência e esperamos produzir a melhor métrica de autoridade da página que já publicamos.